Among the many emerging capabilities of large language models (LLMs), one of the most powerful is their ability to translate natural language into structured actions via API calls. This concept is formalized as “tools” in the OpenAI API. Model Context Protocol (MCP) builds on this idea by decoupling tools into standalone servers and clients. The result is a dynamic, agentic architecture where components can be composed, discovered, and orchestrated in real-time.
At LitenAI, we’re developing AI agents for data engineering, and we’ve adopted MCP to power them in production environments. In this post, I’ll walk you through how we used MCP to build a research agent that answers any question by recursively refining a prompt, conducting live web searches, and summarizing the results.
Agent Overview
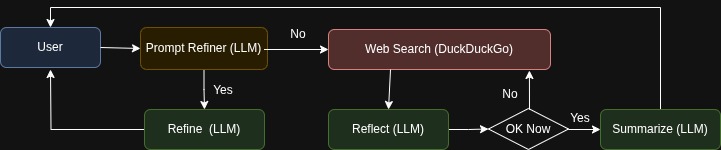
The research agent is composed of three parts:
- Prompt Refiner: Refines the user’s input into a clearer research question.
- Web Searcher: Conducts iterative web searches using DuckDuckGo with AI reflections.
- Summarizer: Synthesizes the search results into a professional report.
Here’s how the architecture works:
Step-by-Step Code Walkthrough
Let’s dive into the core components of the agent.
1. Environment Setup and Imports
We begin with the usual imports and initialization:
from openai import OpenAI
from duckduckgo_search import DDGS
from mcp.server.streamable_http_manager import StreamableHTTPSessionManager
…
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
We also prepare a base message list to keep track of the conversation for refining prompts.
2. Prompt Refinement Function
This function uses OpenAI tools API to refine a vague user input into a sharp research prompt.
def refine_prompt(messages, prompt: str) -> tuple[bool, str]:
tools = [{
'type': 'function',
'function': {
"name": "refined_prompt_tool",
…
}
}]
messages.append({
"role": "user",
"content": f"Refine this topic into a clear research question: {prompt}"
})
completion = client.chat.completions.create(
model="gpt-4",
messages=messages,
tools=tools
)
…
The function returns a tuple: the refined prompt and whether the user accepted it. MCP Server interacts with User till the prompt is refined.
3. Recursive Web Search
Once a refined prompt is ready, we search using DuckDuckGo API. We then ask the LLM to reflect on the result, and give a better phrasing based on it.
def search_and_reflect(search_prompt, research_messages, max_results: int = 2) -> str:
ddgs = DDGS()
results = ddgs.text(search_prompt, max_results=max_results)
for i, result in enumerate(results):
research_messages.append({
"role": "assistant",
"content": f"[{result['title']}]({result['href']}): {result['body']}"
})
research_messages.append({
"role": "user",
"content": "Can you suggest a more focused follow-up search?"
})
completion = client.chat.completions.create(
model="gpt-4",
messages=research_messages
)
return completion.choices[0].message.contentWe repeat this step iteration times (default 2–3) to improve coverage.
4. Summary Generation
Finally, we prompt the LLM to synthesize the entire research thread:
research_messages.append({
"role": "user",
"content": "Write a concise and professional research summary from the context."
})
final_response = client.chat.completions.create(
model="gpt-4",
messages=research_messages
)
summary_text = final_response.choices[0].message.contentThe summary becomes the output of our tool.
Wrapping it All in a MCP Server
To make this a deployable tool, we wrap the whole logic inside an MCP server with HTTP streaming support:
@app.call_tool()
async def call_tool(name: str, arguments: dict) -> list[types.TextContent]:
…
return [types.TextContent(type="text", text=summary_text)]
...
session_manager = StreamableHTTPSessionManager(
app=app,
event_store=None,
json_response=json_response,
stateless=True,
)
Run it with bash from the github directory.
uv run mcp-research-agent
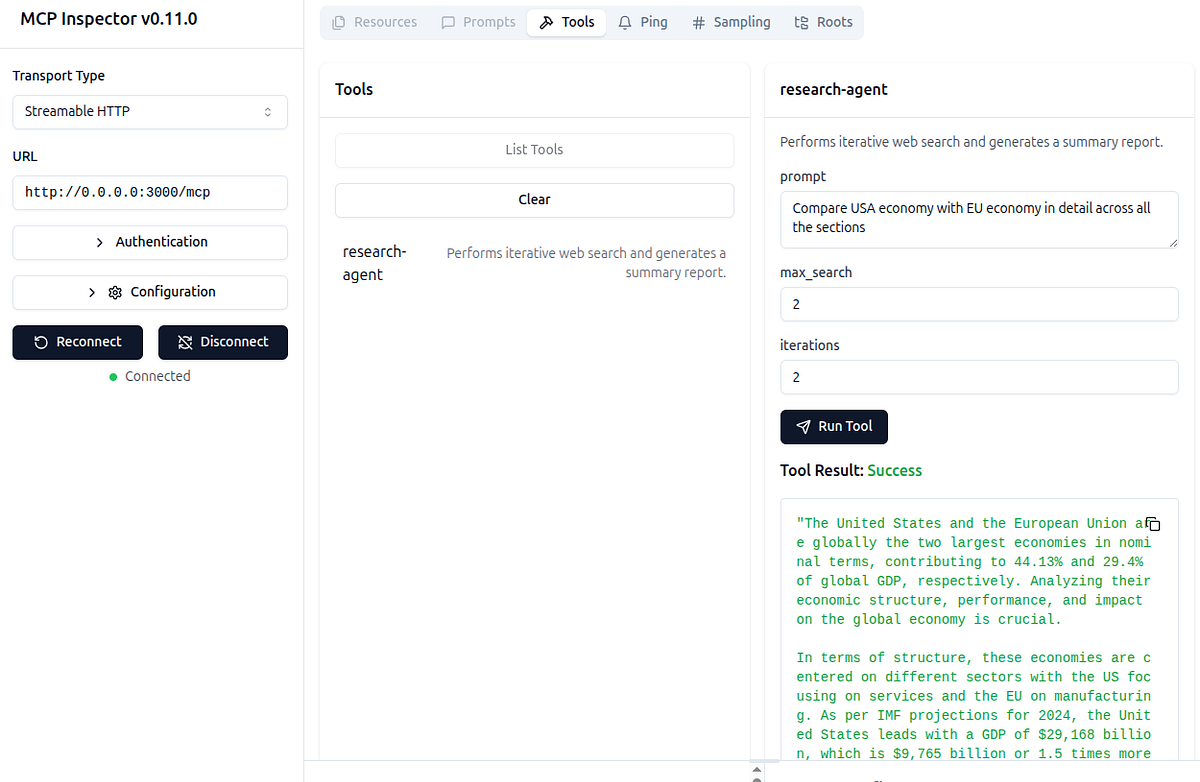
This can be tested using an MCP Inspector. See here for a test output image.
Why This Matters
Deploying MCP agents like this is non-trivial. Production workloads demand HTTP(S), secure data handling, and multi-node stateless operation. MCP now supports HTTP streaming, making it easier to deploy agents using standard protocols. This unlocks the possibility of plug-and-play agents that can interact with enterprise systems behind firewalls.
At LitenAI, we’re building AI agents to automate reasoning on enterprise data. This research agent is just one example of how MCP and LLMs can power complex, multi-step workflows in production environments.
Try it Yourself
Want to explore the code? It’s available here:
https://github.com/hkverma/research-mcp-agent
We at LitenAI love to hear your feedback or collaborate on use cases. Reach out!