Our customers’ support operations generate vast amounts of data, including knowledge documents and structured data like machine logs. LitenAI Smart Lake securely stores this data, scaling efficiently to handle petabyte-level volumes at a competitive cost. The stored data is fully secure and accessible only to customers. LitenAI Agent leverages this Smart Lake to provide accurate and relevant answers to technical questions.
Modern enterprises are witnessing an unprecedented surge in data creation, with vast amounts of information being generated continuously. This growth aligns with significant advancements in cloud technology, particularly through dis-aggregated systems. Despite continuous progress in hardware capabilities, organizations face growing challenges in meeting the escalating demands for performance improvements, reducing cycle times, and lowering computational and cloud costs. Simultaneously, they are under pressure to achieve sustainability targets.
The LitenAI Smart Data Lake securely stores all documents and structured data in a unified storage environment. This data is exclusively accessible to customers and is never shared with third parties. The lake’s open architecture allows customers to access their data seamlessly from any tool of their choice.
By leveraging a unique tensor representation and delta lake compression, which reduces data size by 2-5x, LitenAI data agents accelerate query performance by an extraordinary factor of 10-100x. This innovation empowers organizations to achieve the dual objectives of enhanced performance and sustainable computing, all while significantly reducing costs in an increasingly competitive landscape.
The LitenAI agentic flow integrates seamlessly with the smart lake, simplifying observation and reasoning processes to deliver actionable insights efficiently.
Open, secure, integrated big data store
The LitenAI Smart Data Lake leverages the open Delta Lake format with a tensorized representation, enabling seamless integration and accessibility through tools like Spark.
All data is fully owned by the customer, never shared with LitenAI or any third parties, and is 100% secured. Customers can choose to store their data either in the cloud or on-premises, based on their specific requirements.
LitenAI utilizes elastic object storage to partition and index data, enhancing storage efficiency and performance. This architecture allows the data store to scale seamlessly to petabytes of data. Older data can also be transitioned to archival storage, further reducing storage costs.
The modern AI stack significantly improves the ability to search through both structured and unstructured data. The LitenAI Smart Lake stores various types of customer documents, including PDFs, emails, standard operating procedures, HTML files, audio/video files, and other knowledge assets. Additionally, it accommodates structured data in a tabular format. This unified storage enables LitenAI agents to integrate knowledge documents with structured data to deliver customized insights.
Connect to external data sources
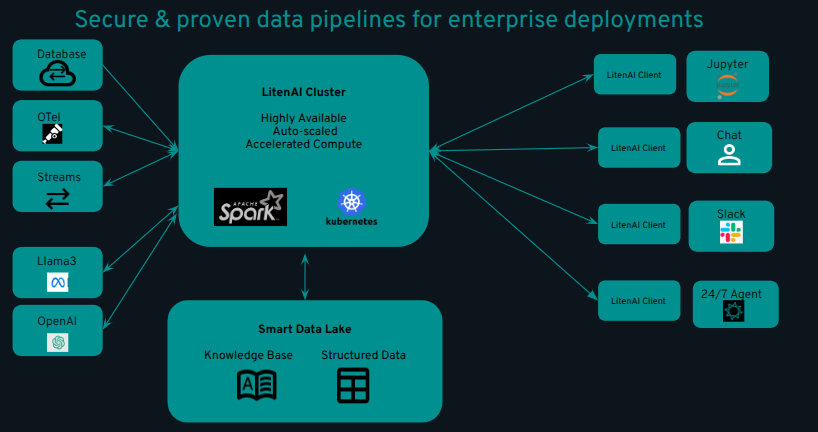
LitenAI seamlessly connects to and ingests data from various external sources.
To handle log files, LitenAI supports OpenTelemetry, enabling the ingestion of data produced by OpenTelemetry collectors. Additionally, it connects to standard databases using dedicated connectors.
For Splunk, universal or heavy forwarders can be employed to transfer data. LitenAI can also collect data from Open Telemetry, process it to filter unnecessary information, or join it with other datasets before sending it to other tools or storage, significantly reducing operating costs.
LitenAI leverages the Spark stack with enhanced Delta Lake storage, allowing customers to utilize a standard big data stack for seamless data modification and analysis.
Reduced Storage Size
LitenAI utilizes a compressed binary format for data storage, enabling customers to filter out unnecessary information effectively. This method reduces storage requirements by 2-5x, significantly enhancing storage efficiency and optimizing costs.
By leveraging a dis-aggregated storage model, LitenAI provides cost-effective solutions, delivering substantial savings compared to traditional tools like Splunk or Datadog.
Integrate semantic and structured search
LitenAI agents leverage Python to generate SQL code for structured searches on the data lake. By also storing semantic representations of documents and tables, these agents enable advanced semantic searches within the lake.
Furthermore, LitenAI agents integrate these documents into a Retrieval-Augmented Generation (RAG) flow, seamlessly incorporating customer knowledge to enhance system functionality.
Accelerated Data Queries
LitenAI Agents are interactive tools designed to provide a customer-friendly experience. Query performance plays a crucial role in ensuring their effectiveness. Traditional big data tools, often used for batch processing, can be slow to respond. LitenAI overcomes this limitation by optimizing storage and enhancing the query engine, delivering faster, more interactive responses.
Current relational and tabular data platforms often struggle to keep pace with emerging technologies. LitenAI tackles this challenge with a unique tensor representation that enables data agents to accelerate queries by a factor of 10-100. By converting incoming data into a tensor-formatted columnar structure, LitenAI optimizes processing and leverages advanced solutions to dramatically enhance query performance. Additionally, LitenAI integrates seamlessly with Spark clusters and efficiently ingests data from various data stores.
Benchmark TPCH Query
The Transaction Processing Performance Council (TPC) establishes industry-standard benchmarks for evaluating data and query performance. TPC Benchmark™ H is a decision-support benchmark. Our tests focused on Query 5 and Query 6 of TPC-H due to their complex joins and extended query plans. These tests were conducted using a standalone Spark cluster and a dedicated LitenAI service. LitenAI significantly enhanced query performance with its tensor-based engine, utilizing an in-memory tensor cache to avoid redundant processing and optimize efficiency.
TPCH Query 5
This query calculates the revenue generated from local suppliers.
LitenAI accelerates this process by replacing traditional joins with efficient multi-dimensional lookups using tensor data. This approach streamlines operations by minimizing shuffle operations, resulting in significantly faster query execution.
The accompanying diagram illustrates the streamlined plan and demonstrates how LitenAI optimizes this process.

With LitenAI, query plans are simplified. Once a tensor is created, joins are replaced with multi-dimensional lookups, drastically reducing data shuffling between nodes and accelerating query performance.
On an Azure DS2 VM, Spark 3.2 required 31 seconds to execute the query, while LitenAI completed the task in under 2 seconds, achieving over a 15-fold performance improvement.
TPCH Query 6
This query evaluates the potential revenue growth by eliminating company-wide discounts.
LitenAI significantly streamlines the query plan, as illustrated in the accompanying diagram.

With LitenAI, the query plan is simplified, enhancing scan and aggregate operations. On a standard Azure DS2 VM, Spark 3.2 required 16 seconds to execute this query, whereas LitenAI completed it in less than 1 second, delivering a performance improvement of over 15x.
Summary
LitenAI offers a big data solution capable of storing limitless log data. It employs industry-standard open data lake formats for data storage. It is designed with AI first in mind. LitenAI Agents use smart data to provide an intelligent conversational interface to get insights from LitenAI data lake.